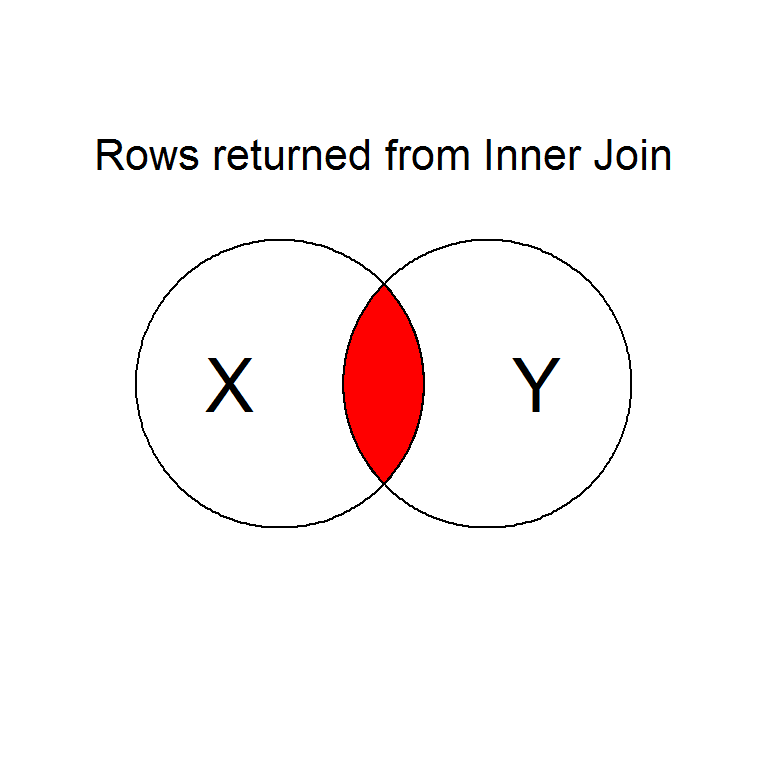
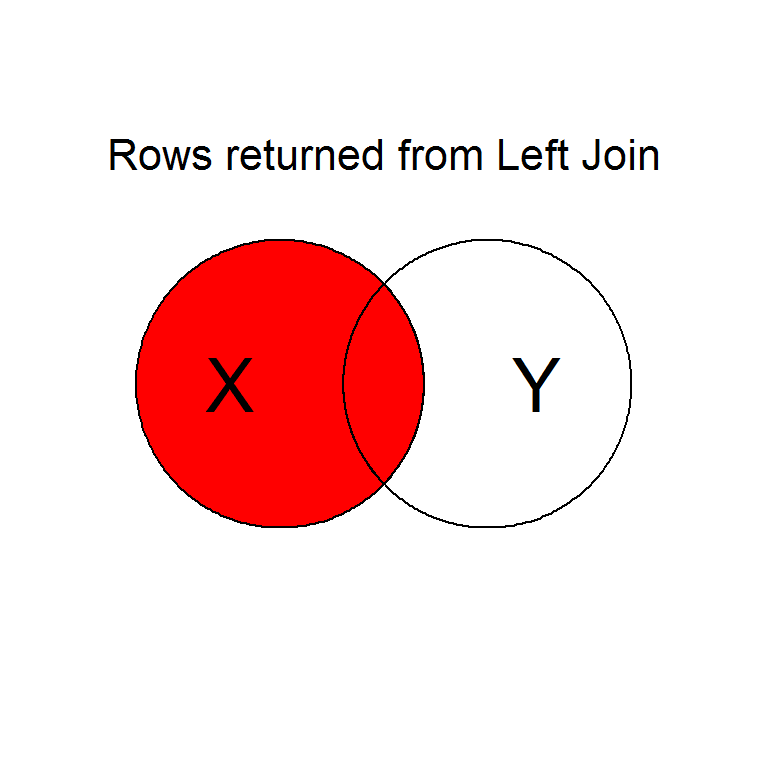
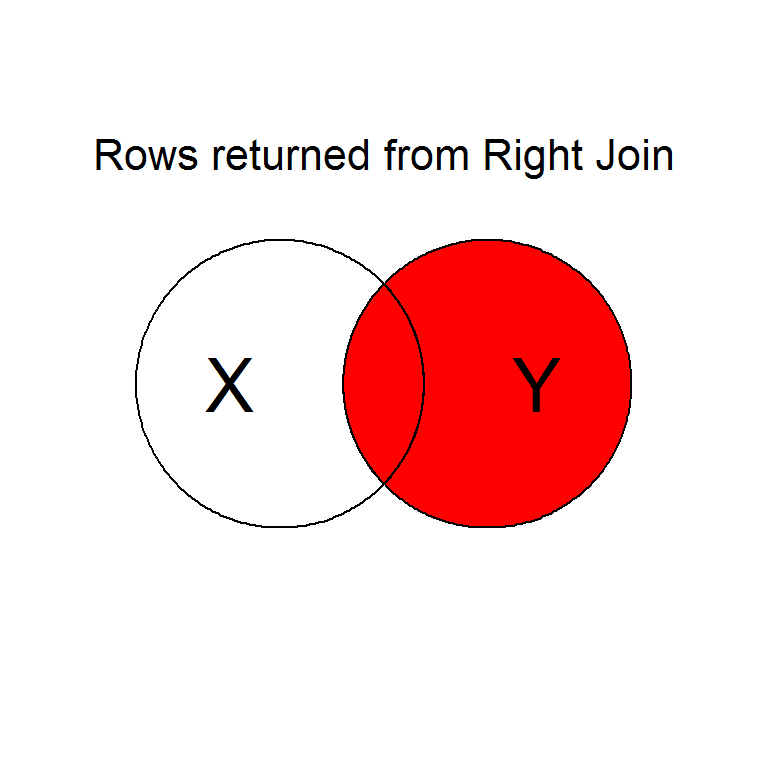
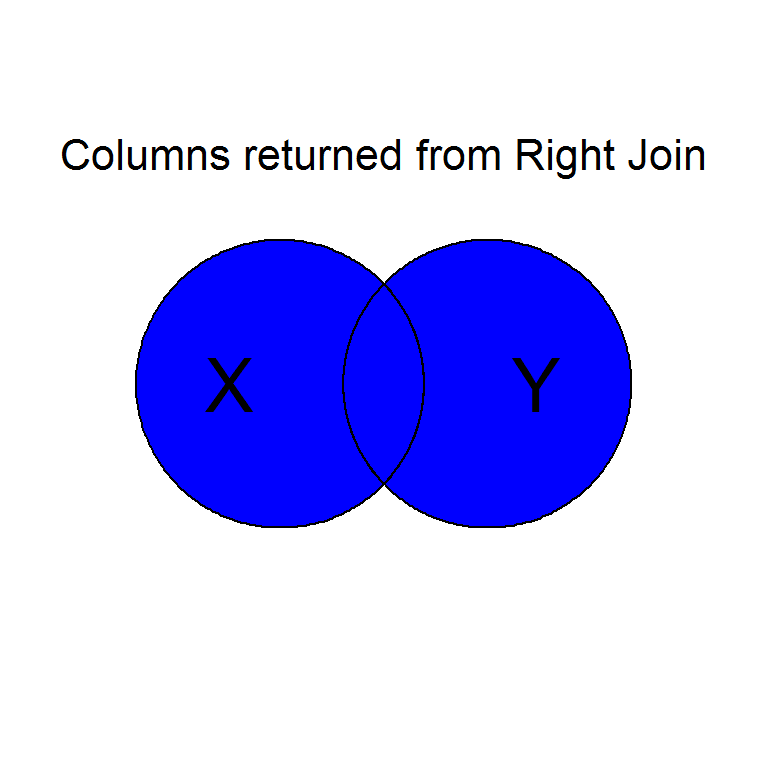
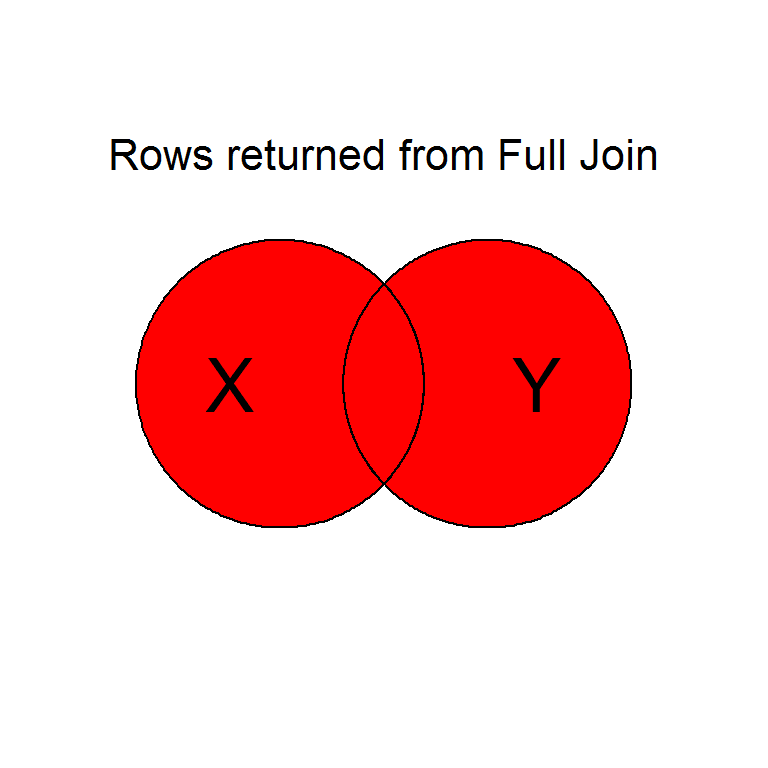
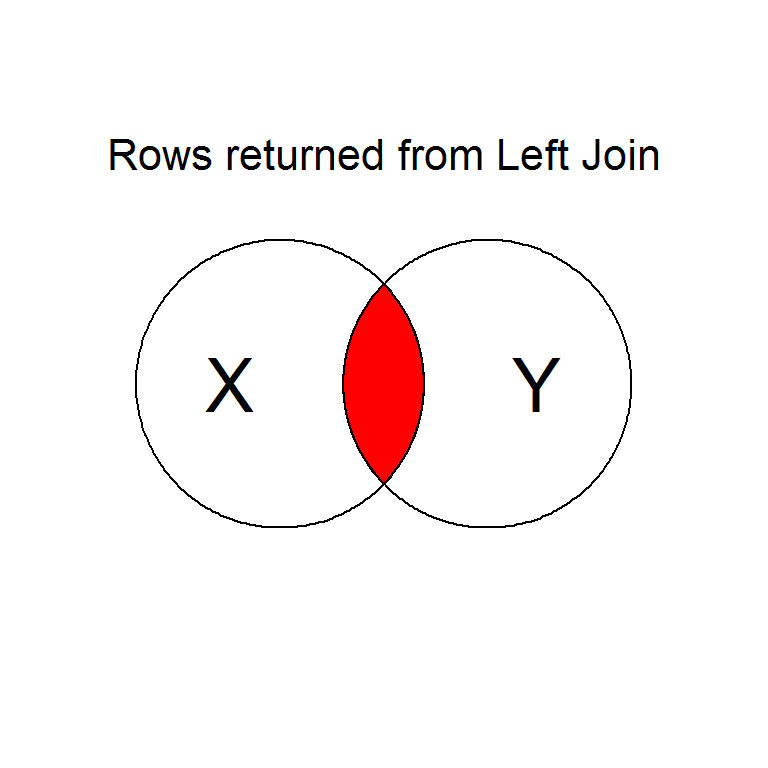
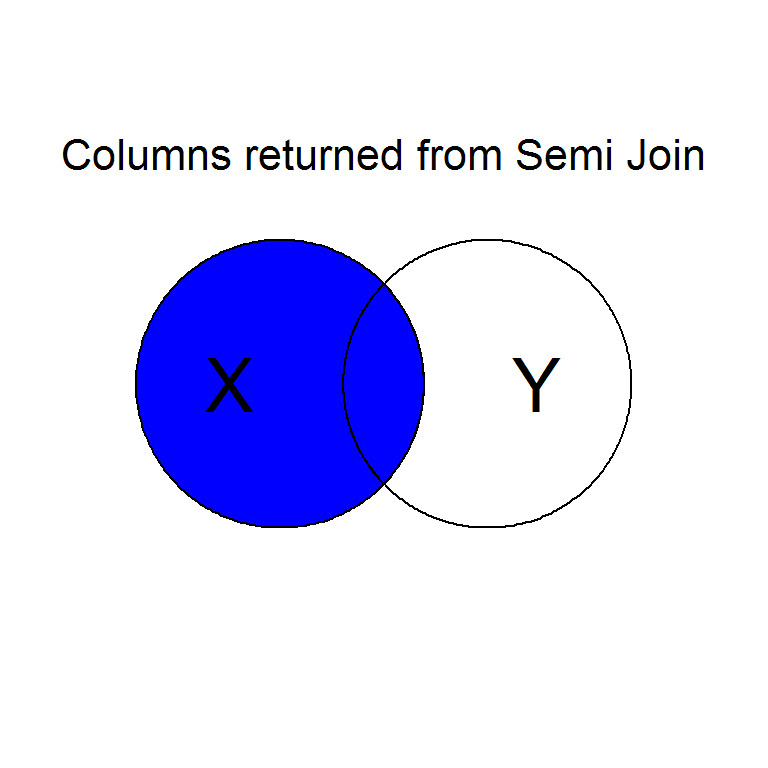
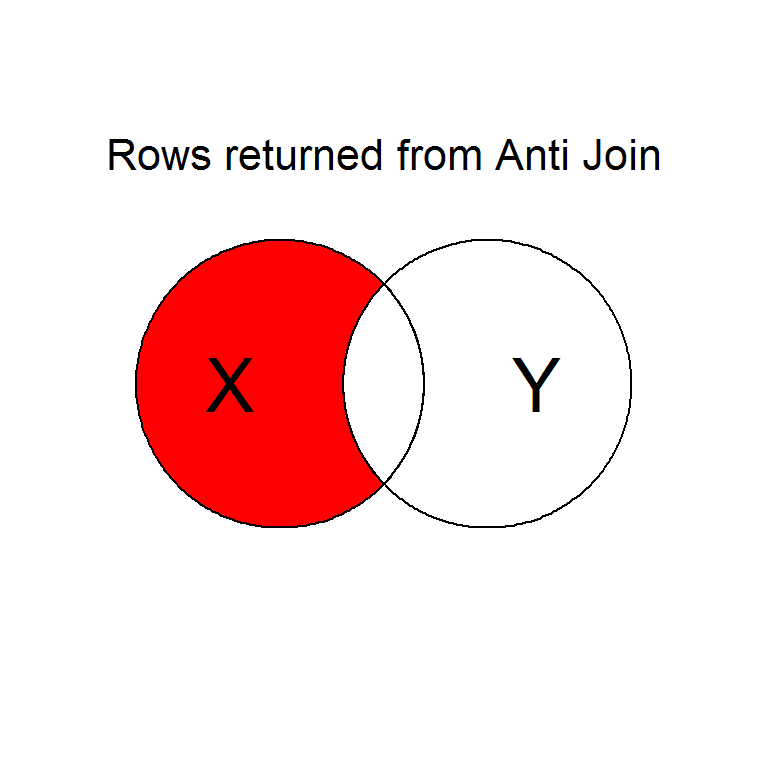
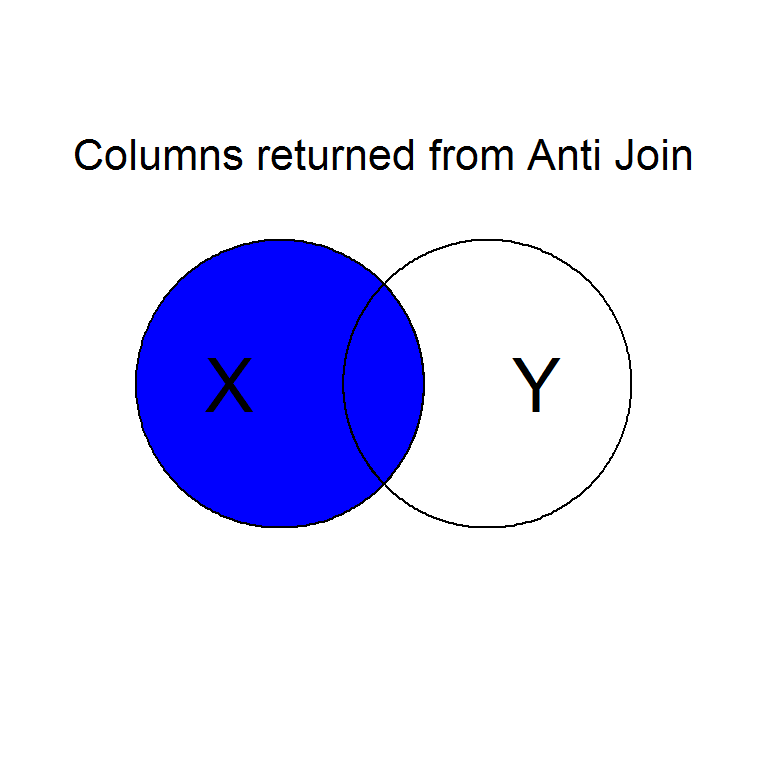
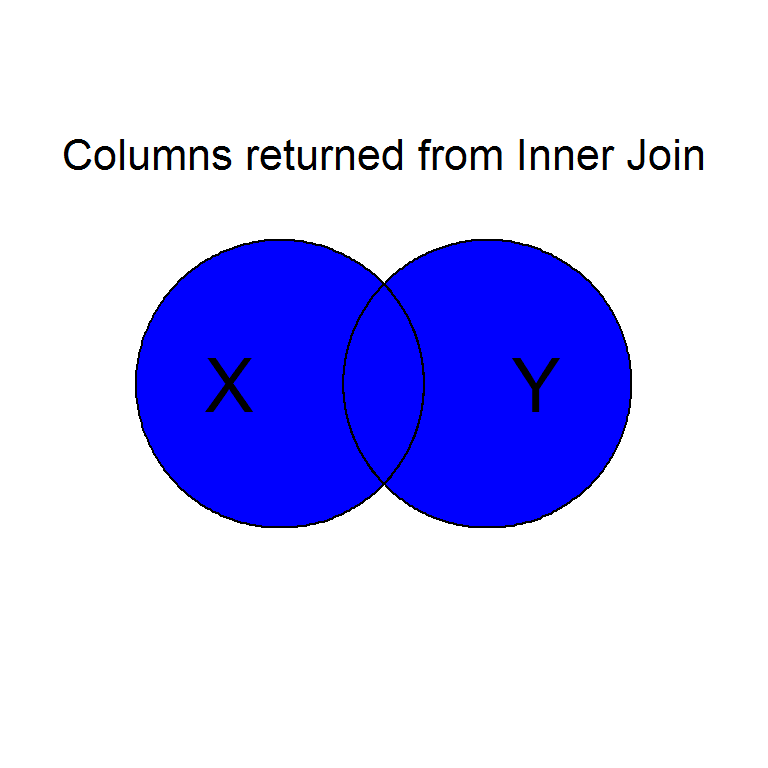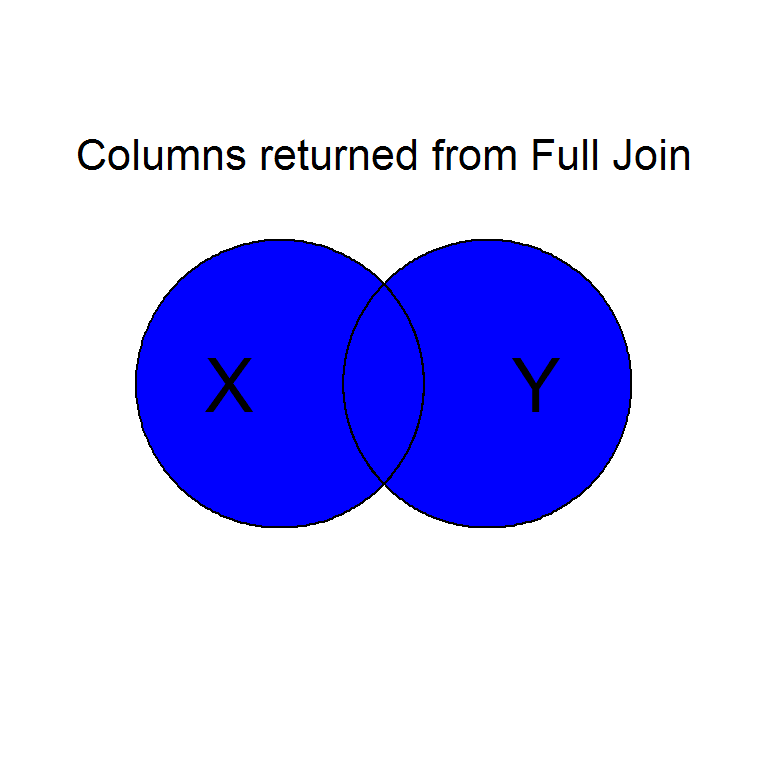Intentionally or unintentionally, its common to find yourself needing to merge two data sets into a single one.
- To make plotting simpler
- To make a table
- More easily subtract variables
- Cross check for errors/missing values
If these two data sets have exactly the same variables (i.e., the same column names measuring the same things) this is a simple task.